-
ADAMA: Autonomous Distributed storAge with Multiple Access for the fog computing [CHISTERA, PI: Banoit Parrein]
- Fog computing provides a dedicated distributed system as a closer infrastructure for the Internet of Things (IoT). The expected outcome is improved User Experience (UX) in terms of reactivity, reconfigurability, reliability and ubiquity. A couple of propositions are already made in the literature to specify such network of resources but none of these successfully combine scalability and performance. In this project, we propose to combine decentralization with P2P networks and generic Scale-out Network Attached Storage (NAS) architecture with the use of various smart techniques to be able to address this goal. Last year, the team of the coordinator proposed such a software architecture in a static way producing very promising results. The main objective of this project is, therefore, to further investigate the dynamic situations in which the potential unavailability (transient or permanent - or strugglers in a distributed context) of Fog sites/nodes do not necessarily disturb the operating performance of the entire distributed system such as end-to-end delay. With this project, system-level intelligence will be incorporated to achieve this fundamental goal including novel coded computation techniques, smart caching and innovative protocol designs all geared towards better UX. The final use case is a perfect edge distributed infrastructure for a network of mobile robots for multiple distant warehouses in an Industry 4.0. The consortium of the project is perfectly designed to provide complex distributed storage systems at the Fog and Edge layers by considering the dynamic network interactions and the improved final UX.
Here are some of the past projects (2016-2022)
-
Development and testing of concurrent algorithms to solve mixed integer linear programming problems in distributed memory systems [Supported by TUBITAK 3501 - 219M080. PI:Utku Koc]
- The clock speed of the high-tech processors is more or less stable for the past decade. Computer technology is now mainly focused on increasing the number of processors and memory. With this in mind, it is inevitable that algorithms and methods used in parallel processors in distributed memory systems are the trend in all areas. The number of processors on personal computers is rapidly increasing and the opportunities offered by businesses such as Amazon and Google have made distributed memory systems available for enterprise and even individual use where concurrent algorithms can be run on cloud systems. From a practical point of view, it is important to solve a problem or identify a good solution within a reasonable amount of wall-clock time, de-emphasizing the CPU-time used. Mixed Integer Linear Programming (MILP) models are used in many applications such as production planning, energy, distribution, health, telecommunication, and logistics. The size and variety of the data generated and stored every day on a global scale is increasing and the analysis of big data becomes more important. With the increasing amount of data, larger MILP models need to be solved. In recent years, the development of linear programming problems has been limited in both computational and methodological considerations, but the development in MILP models has been even further (Lodi, 2010; Gleixner, 2019). It is necessary to develop MILP solution methods that work concurrently in distributed memory systems using up-to-date technologies. There is no published work on heuristic and cutting plane methods implemented in distributed memory systems. This project is the first attempt for concurrently running alternative heuristics and cutting plane algorithms in parallel. This will give a head start for the principal researchers career, leading to follow-up projects. This project aims to develop an MILP solution framework that can solve MILP problems in distributed memory systems, where subroutines run concurrently, starting from different points, and asynchronously share information amongst themselves. This framework needs to be robust and stable against problems that can occur in the distributed memory environment. The proposed concurrent optimization framework will allow simultaneous operation of both heuristic and cutting plane algorithms. The effects of starting from different points, information sharing and concurrent implementation will be identified, and the scalability of methods will be tested for the first time in the literature. Having researchers from the computer science and industrial engineering departments will lead an increase in the interdisciplinary working abilities for the research team. The principal researcher will gain skills in parallel programming and cutting plane algorithms. The researcher will acquire new skills in optimization. The effect of the project is twofold: 1) The research team is planning to share the results via 2-3 papers in SCI or SCI-Exp indexed journals, 2-3 presentations at international and 2-3 presentations at national conferences. 2)A computational improvement in solving MILPs will lead an increase in solvable problem size and/or reduce solution times for relevant problems that academicians and practitioners face. In the proposed parallel optimization framework, both heuristics and cutting plane algorithms will start from linear programming relaxation as well as alternative random interior and vertex points near an optimal solution. The information generated in the subroutines will be asynchronously shared so that a valuable information detected in any subroutine will be used collectively by all subroutines. For heuristic and cutting plane methods, the effects of starting from different points, asynchronous information sharing and concurrent running will be determined independently of each other and the scalability of the method will be tested.
-
DeepBCI: Improving the Transfer Rate and Decoding Accuracy of Brain Computer Interface Communication via Deep Learning and its Application to P300 Spellers [Draft Phase, PI:Huseyin Ozkan]
- Brain-Computer Interface (BCI) is an extremely important tool for individuals with severe motor disabilities. Additionally, in other engineering fields such as drones, augmented reality, high-speed trading, defense and gaming, BCI is expected in near future to lead to unprecedented impacts thanks to its high application potential. On the other hand, due to the low information transfer rate and low decoding accuracy in the state-of-the-art of this technology, BCI could not yet have found many widespread production-ready applications. This project focuses on the event-related electroencephalography (EEG) potential (Event Related Potential, ERP)-based BCI speller (especially P300, but inclusive of other OBPs as well) applications, while addressing these two known issues as the main objective. In the proposed highly innovative solutions and highly novel technical approach to the speed and accuracy problems regarding character recognition, we have a deep learning-based statistical modeling enhanced by concatenated and error correction codes (ECC) of information and coding theory, along with generalized class binarization. To this end, a front-end ECC ERP determines the timing of BCI flashing patterns, which is followed by our deep learning architecture that performs feature learning and character recognition. The deep learning architecture consists of a convolutional neural network (feature learning), a bi-directional recurrent neural network (handling data correlations), a multi-layer perceptron (character recognition through detection of ERPs), and a variational autoencoder (likelihood maximization). The output of this architecture is another problem-dependent error correction output code (ECOC), and this provides strengthened reconstruction for character recognition. The back-end code error rate provides feedback signals to front-end coding and determines an ECC-ECOC feedback framework for optimizing the BCI flashing patterns. In the design of deep learning architecture units and EEG preprocessing stages, machine learning (e.g., random kernel expansions) and advanced signal processing (e.g., independent component analysis) is utilized. The main aim of the project is to develop a unique BCI system, 1) which is expected to create a high positive impact on the lives of users (especially the disabled) and 2) which efficiently exploits the mentioned powerful techniques to a systematic joint design for making novel contributions to the scientific literature. The project radically differs from the existing literature/BCI-solutions thanks to its highly innovative technical approach including the design of an unsupervised (without requiring the label information/calibration) online learning framework, and therefore it will attract great attention from the research communities as an interdisciplinary (information and coding theory, deep learning, machine learning, signal processing, BCI, neuroscience) research program.
-
DISCO-Proc: DIstributed Storage, near-optimal COding and Protocol design for data caching in cellular networks [Now Supported by TUBITAK 1001 - 119E235, PI: Suayb S. Arslan]
- In cellular networks, with the caching of popular files in devices, the communication between devices significantly reduces the communication load on the base station (BS). This can be accomplished by distributing the partitions of a popular file to mobile devices either in an uncoded or coded form using erasure coding. Any piece of the chunked content can either be retrieved from the neighboring mobile devices or, if not possible, from the BS directly, at the expense of a higher communication cost. Considering a cellular network, in which a cell contains a set of nodes, some of which are arriving and some are departing at random times, intelligent data repair methods will be needed to ensure a minimum level of communication with the base station (BS). Involvement of a BS or more than one BS adds another dimension to previous repair paradigms, especially to the cooperative repair process due to the changes in the set of constraints and operating protocol rules. There is no work which studies the bandwidth/storage trade-off for this particular case. Accordingly, novel cell architectures will call for different design considerations including but not limited to novel code constructions, protocol designs, data access latency, realistic queuing models and simulation platforms. In this project, unlike the previous research, we initially aim to obtain improved theoretical bounds for the bandwidth and storage capacity using data flow diagrams while BSs are cooperatively helping to repair the lost data. In addition, inspired by the code structures that utilize bandwidth and storage space efficiently, completely genuine graph-based code constructions as well as novel repair algorithms on these codes will be proposed to achieve near-optimality. Novel approaches such as genetic algorithm and optimal left-over data distributions shall be proposed that have not previously been applied to the node repair problem in literature. Besides that, highly novel protocol designs based on energy efficiency for check-in and check-out processes, will be proposed, which will help minimize the bandwidth and data storage requirements. These protocols will be strengthened by transition (hand-off) scenarios, which will allow nodes to migrate from one cell to another, while enabling the BSs to collaborate and help effectively use the intracellular resources. This involves few novelties such as adjusting repair intervals (thresholds), reducing data access overheads, the use of incoming node contents, intelligent left-over data handling etc. Finally, various known and more realistic queuing models will be used to analytically evaluate the proposed code structures and the performance of the protocol architecture. In order to verify our analytical results, large scale cellular network simulations will be performed in order to numerically derive overall communication and file maintenance cost as well as comparisons.
Prilimanary Work:
- Haytaoglu, E., Kaya, E., Arslan S. S., "The Fault Tolerant Distributed Data Caching for Mobile Devices using LDPC Codes", 2019. [progress_report.pdf] - Not complete.
- Arslan S. S., Haytaoglu, E., "On Data Access Latency of Network Codes", 2019. [progress_report.pdf] - Not complete.
-
Cold Storage and Reliability/Availability Modelling [Now supported by Quantum Corporation]
- Power efficiency and renewable energy are at the forefront for any technology including but not limitted to digital long-term data stoage. As the growth of data has seen unprecedentedincrease, the storage costs of giant data centers multiplied. Hence, cold storage has emerged as the new paradigm to store digital data without much energy spent. As each new technology requires novel tehcniques to format, protect and make it available to user, cold data storage (particularly for archival use cases) has its own peculiar requirements. Looking forward, every country must think about and strategize their data future, and storage lays at the heart of this agenda. In this project, we lay foundations for each and every aspect of digital cold data storage based on Tape and DNA systems. We propose coding strategies, algorithms, reliability and availability models, accessibility straategies, etc. to be able to embrace green data storage opportunities for power-hungry future. This project also considers advance discrete time simulations for numerically modelling Tape/optical disk librarries as well as teoretical Markov modelling to estimate availability in scale-out settings. This project has been supported by Quantum Corporation, Irvine, CA between 2015-2019.
-
Implementation of AI using Quantum Information [Draft Phase]
- The computation models of various AI schemes contain lengthy training phases to achieve a reasonable accuracy. Under ideal cases, quantum mechanics can be utilized to speed up conventional training exponentially. One of the research directions is to implement the most basic AI unit known as the simplest model of an artificial neuron, perceptron. There have several primising attempts in the literature since 2014, but none has converged to a single best solution. In addition, the nonlinearity of the measurement process used to implement thresholding provides only an approximation. Plus, quantum states being vulnerable to environmental conditions may lead to various types of faulty behaviours (collapse) which shall in turn affect the algoritm's accuracy. Hence, the main objective of this project is to implement fault-tolerant and efficient quantum processing devices for AI and machine learning applications.
-
Drive Failure Modeling
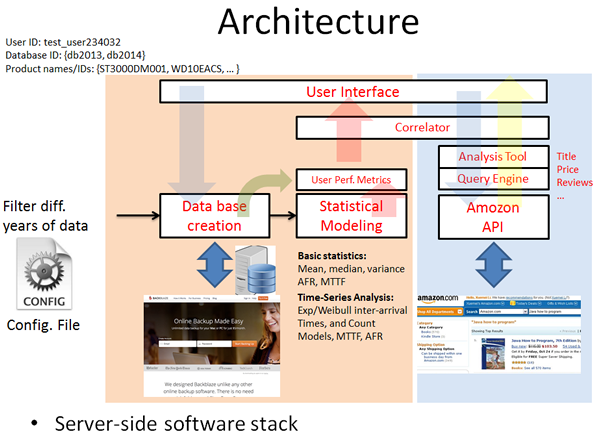
- This is a part of TUBITAK 2232 project and aimed at finding accurate device failure modeling using higher order statistical models. This study would include hidden markov models, data fitting, estimation of inter-arrival rates as well as count models. This study is part of a larger application the summary of which is pictured below. The service development shall provide the outcome of our modeling study as well as various other data such as amazon price, quality of the product based on reviews, factual data from the database etc.
As mentioned, the project has different components:
1. Large database of disk or SSD drives with SMART and health information electronically store. It is hard to record all that data by myself so i would like to thank Backblaze who provides such data for analysis which is based on around 50K different HDDs in their data center. One of the components of our software takes the data and generates an appropriate database.
2. Another component of this study is to develop programs to do the modelings and enlarge the database with the new results for each drive indicating more accurate health information such as MTTF, MTTDL, predicted AFR etc.
3. Finally, last component is to consult other webpages such as amozon to collect information about drives to enrich the contents of the databases which we can later use to share with users based on their filtering options through a thin web interface.
Founsure 1.0
Founsure 1.0 is the very first version of a totally new erasure coding library using Intel's SIMD and multi-core architectures based on simple XOR operations and fountain coding. This library will have comparable performance to Jerasure library by Dr. Plank and yet shall provide great repair and rebuilt performances which seem to be the main stream focus of erasure coding community nowadays. You can find more information about this project here.
-
Hadoop Project
-
Sorry to say that but this is yet another version of hadoop, an open source framework for processing and querying vast amounts of data on large clusters of commodity hardware. A comprehensive intro can be found at here.
- This project has sparked energy and interest when I was involved with Big Data applications at Quantum. Original distribution of Hadoop had the following issues:
-
-
■ Whenever multiple machines are run in cooperation with one another in parallel, ideally in sync'ed fashion, the probability of failures become a norm rather than an exception. These failures include but are not limited to switch or router breakdowns, slave nodes experiencing overheat, crash, drive failures and/or memory leaks. There is not built-in protection mechanism within the original design of Hadoop except replication of the same object in different clusters, which might be very costly.
-
■ No security model is defined. No safeguarding against maliciously inserted or improperly unsync'ed data.
-
■ Each slave compute node has limited amount of resources, processing capability, drive capacity, memory and network bandwidth. All these resources should be effectively used by the overlaid large-scale distributed system. For example, replication of data at various compute nodes for data resiliency is an inefficient way of providing data protection.
-
■ Syncronization of compute nodes remain another important challenge that a distributed system design is aimed at solving. Async operations leads some of the nodes to be unavailable, in which case the compute operations must still continue, ideally with only a small penalty proportional to the loss of some computing power.
-
- Under these circumstances , the rest of the distributed system should be able to recover from the component failure or transient error condition and continue to make progress for processing intensitve applications. In addition, the progress must be responsive, fast and secure. Providing all these nice features is a huge challenge from an engineering perspective.
Objectives
Main futures of this project include:
■ Data protection - Purely XOR-based extremely fast and efficiently repairable erasure coding (I do not know how much i can disclose on that....But it will defintely be possessing better features than LRC of Mcrsft (so to name Xorbas of FB) and probably R10-Raptor type codes). Original design of erasure codes do not in general respect to the peculiar requirements of data storage businesses. Practical coding strategies that address data storage requirements is a huge challenge and we intend to provide one tangible solution in this project. It is also intended to bring data-sensitive durability concept into the picture and protect data based on user's durability goals in a hybrid cloud environment. This part of the project involves modifications in HDFS layer.
■ Data integrity/security - Sensitive data aware MapReduce (MR) framework for hybrid clouds. It steers data and computation through public and private clouds in such a way that no knowledge about senstive data is leaked to the public machines. The new feature of our secure MR solution brings exploitation of public compute resources when processing the sensitive data. This would lead to remarkable execution time speed improvements compared to other secure MR frameworks.
■ Node Syncronization - minimize the number of unavailable clusters for data processing through intelligent sync algorithms. (More to follow later)
■ Power efficiency of the overall HPC system (large clusters) through HDFS, map-reduce functionality and cluster tagging.
We will update the news as we proceed with the project...please stay tuned.